

Amazon AGI објави дека го развиле најголемиот модел за текст во говор што некогаш бил создаден. Притоа се објаснува дека поимот “најголем” значи дека моделот има најмногу параметри и дека за негова обука била користена досега најголемата база на податоци. Научниот тим на Amazon AGI го опишува равојот и обуката на моделот во научниот труд којшто е достапен на предпринт серверот arXiv.
Големите јазични модели (Large Language Models – LLM) од типот на ChatGPT го привлекоа вниманието со нивната способност да одговараат интелигентно на поставени прашања (слично на човек) и да создаваат документи со високо ниво на детали. Но, вештачката интелигенција сè уште го пробива својот пат кон другите мејнстрим апликации. При ова ново истажување акцентот е ставен на подобрување практичната примена за пренос од текст во говор, со зголемување на бројот на параметри и надградување на податочниот басен за обука.
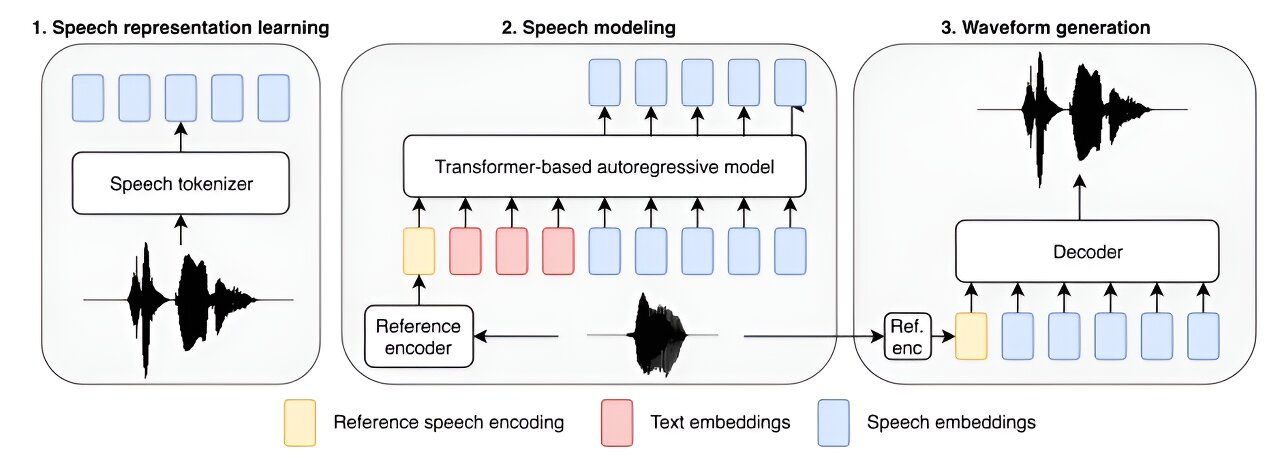
Преглед на BASE TTS. Токенизаторот на говорот (1) учи дискретно претставување, кое е моделирано со авторегресивен модел (2) условен од текст и референтен говор. Декодерот за говорен код (3) ги конвертира предвидените говорни претстави во брановидна форма. СликаКредит: arXiv (2024)/ DOI: 10.48550/arxiv.2402.08093
Новиот модел, наречен Big Adaptive Streamable TTS with Emergent abilities, (накратко BASE TTS) има 980 милиони параметри и е обучен со користење на 100 000 часа снимен говор (најден на јавно достапни сајтови), од кои повеќето биле на англиски јазик. Тимот, исто така, му дал и примери за изговор на зборови и фрази на други јазици, со цел да овозможи моделот правилно да ги изговара добро познатите фрази кога ќе ги сретне – на пример „au contraire“ или „adios, amigo“.
Тимот од Амазон го тестирал моделот и на помали збирки на податоци, надевајќи се дека ќе го лоцира каде моделот го развива она што на полето на вештачката интелигенција се нарекува пројавена способност (emergent quality), при што апликацијата со вештачка интелигенција, независно дали се работи за LLM или апликација текст-во-говор , се чини дека одненадеж се случува скок кон повисоко ниво на интелигенција. Тимот открил дека во нивниот случај скокот кон повисоко ниво се случил при обработка на податочни збирки со средна големина, со 150 милиони параметри.
Тие, исто така, забележале дека скокот вклучува мноштво јазични атрибути, како што е способноста да се користат сложени именки, да се изразуваат емоции, да се користат странски зборови, да се применува паралингвистика и интерпункција и да се поставуваат прашања со акцент ставен на вистинскиот збор во реченица.
Според најавите од научниот тим, BASE TTS нема да биде достапен за јавна употреба поради страв од неетичка злоупотреба, но тие планираат да го користат како апликација за учење. Тие очекуваат да го применат досега наученото за подобрување на квалитетот на човечкиот звук во апликациите текст-во-говор.
Преглед на BASE TTS. Токенизаторот на говорот (1) учи дискретно претставување, кое е моделирано со авторегресивен модел (2) условен од текст и референтен говор. Декодерот за говорен код (3) ги конвертира предвидените говорни претстави во брановидна форма. СликаКредит: arXiv (2024)/ DOI: 10.48550/arxiv.2402.08093