

По еуфоријата, но и стравот што го зафати светот со појавата на ChatGPT, една година подоцна пристигнува првиот регионален голем јазичен модел со 7 милијарди параметри – YugoGPT. Во интервјуто дадено неодамна за порталот на РТС, неговиот творец Алекса Гордиќ откри што идните корисници можат да очекуваат од овој јазичен модел.
Алекса Гордиќ дипломирал електроника на Електротехничкиот факултет во Белград во 2017 година, по што во периодот од 2018 до 2021 година работел како софтверски инженер и инженер за машинско учење во Microsoft Development Center во Србија, на проектот HoloLens од доменот на компјутерската визија. Потоа тој работел во најдобрата светска компанија за вештачка интелигенција – Deep Mind на Google, на јазични модели кои исто така можат да разберат слика и видео.

Алекса Гордиќ, творецот на YugoGPT
На неговиот канал на YouTube Гордиќ ги подучува и другите за вештачката интелигенција, а исто како и на LinkedIn и Twitter (сега: X), тој има формирано поприлично голема заедница. По искуството во најголемите светски компании, одлучил да го искористи своето знаење за создавање на најголемиот регионален генеративен јазичен модел – YugoGPT кој може да го најдете тука.
Генеративниот јазичен модел го тренирате за српски, хрватски, црногорски и босански, заеднички именувајќи го како YugoGPT. Дали сте пионер во ова?
Во моментов нема отворени извори или општо јавно достапни големи јазични модели кои добро функционираат за „нашите“ јазици. Под јавно достапни, мислам на јазични модели кои немаат пермисивна лиценца, кои можат да се користат исклучиво за истражување, но не и за комерцијални проекти. Ние дури ни тоа го немаме. ChatGPT работи доста добро за српски, но проблемот е што вие немате пристап до моделот што стои зад таа услуга. Ова е голем проблем за компаниите што ги ценат нивните податоци и, кои поради приватност или од безбедносни причини, не смеат и не сакаат да ги испраќаат до американските API како ChatGPT.
Мојот модел е во моментов најдобриот јазичен модел за српски, босански, хрватски и црногорски јазик. Се покажа дека е подобар и од моделот Llama 2 изработен од Мета (поранешен Фејсбук), како и од јазичниот модел 7B на Мистрал, при што Мистрал е стартап-еднорог со вредност од 2 милијарди долари, додека Мета е компанија од речиси трилиони долари.
Што точно значи обука на јазичен модел, какво знаење и ресурси се потребни за тоа?
Обуката за јазичен модел подразбира собирање на огромна количина текст од Интернет и потоа помиинување на тој текст низ огромни невронски мрежи на стотици, понекогаш дури и илјадници графички картички. Сето тоа трае со недели, а понекогаш дури и месеци, а во текот на овој процес невронската мрежа учи како да извлече интересни обрасци од текстот. Ја учи граматиката и синтаксата на јазикот, учи како да брои, како да резимира текст и разни други вештини.
За обука на ваков комплексен систем потребни се многу вештини кои се дефицитарни на глобално ниво и затоа на вакви проекти обично работат десетици експерти. Добро познавање на математика, софтверско инженерство, разбирање на НЛП, обработка на податоци, визуелизација на податоци итн. Во овој случај имам големо искуство, од многу различни области, така што сум способен да го направам сето тоа сам, но секако дека би било полесно, подобро и побрзо со поголем тим и повеќе пари. Исто така, пристапот до десетици графички процесори е неопходен за обука на таков систем во догледна иднина.
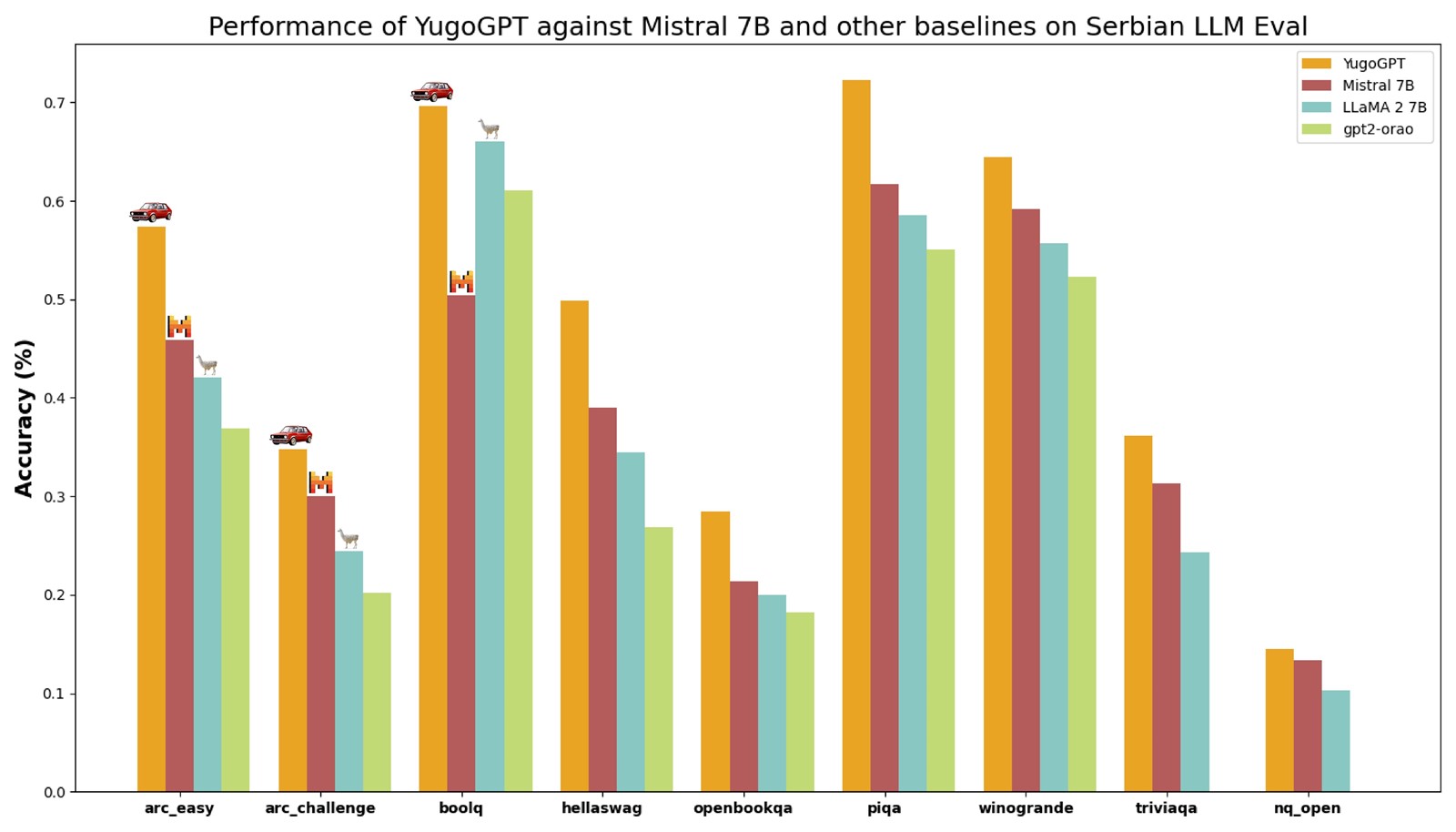
Споредба на перформансите на yugoGPT со другите јазични модели
Што ќе може да „направи“ YugoGPT?
Доколку сте запознаени со функционалноста на ChatGPT, YugoGPT ќе има слични можности. Дополнително, бидејќи поединците и компаниите ќе имаат пристап до параметрите на моделот, тоа овозможува поголема флексибилност, така што од него може да се направи експерт за финансии, даноци, психологија и слично, се разбира, со курирање на резултатите што излегуваат од моделот во случај на чувствителни апликации.
На техничка страна, моделот може да се квантизира – и на тој начин да се направи помал. На тој начин компаниите можат да заштедат пари. Со ова, се губи дел од точноста на моделот, но важно е да се поседува таа контрола, таа моќ и да одлучите што најмногу одговара за вас и вашиот бизнис, наместо OpenAI да одлучува за вас.
Зошто треба да се развиваат регионални екосистеми?
Постојат голем број причини зошто ова е толку важно: културолошки – во време кога вештачката интелигенција и дигиталните системи воопшто, стануваат дел од секојдневниот живот со кој комуницираат нашите деца, сакате системи што зборуваат на вашиот јазик и ја познаваат вашата култура, за да не ги изгубите. Технички, оваа технологија решава проблеми кои до неодамна беа надвор од опсегот на тогашната технологија, речиси дел од научната фантастика. Економски – како резултат на решавање на некои класи проблеми, се отклучуваат нови извори на приход, нова вредност за локалниот екосистем, за корисниците како и за компаниите и за стартапите.
За што сѐ може да се обучат големите јазични модели?
Главната карактеристика на овие системи е тоа што тие се општи, така што одговорот на ова прашање е – за сè што луѓето можат да направат кога ќе им дадете пристап до тастатурата. Самиот LLM нема физичко тело, така што е ограничен само на светот на електроните, но истражувачите и инженерите работат напорно секој ден за да ги решат и тие типови на привремени ограничувања.
Кога очекувате YugoGPT да биде подготвен?
Обуката на основниот модел е завршена. Моментално сум во процес на подготовка на едноставна веб апликација каде луѓето ќе можат да си играат со YugoGPT. Нешто слично на интерфејсот ChatGPT на кој се навикнати, само што работите се прикажани на српски. Демото ќе пристигне, се надевам, следната недела, а потоа планирам да го отворам моделот, откако ќе направам доволно тестови и ќе се уверам дека тој е безбеден за поширока употреба во нашиот регион.
Инвестициите во еден ваков проект не се мали, колку е значајна поддршката од заедницата и општеството во целина?
YugoGPT беше обучен за 16 A100 графички картички кои ги спонзорираше TogetherAI. Добро сум поврзан во светот на ВИ, па можев „бесплатно“ да го добијам тоа, бидејќи се работи за проект со отворен код. Така што тука конкретно немав никакви проблеми со струјата. Велам „бесплатно“ затоа што поради мојата голема заедница таа компанија има што да добие за возврат – маркетинг и таканаречени моќни корисници на системот, кои можат да дадат вредни повратни информации за нивните системи, за што компаниите сакаат да платат.
Претходниот проект што го развивав, за машинско преведување, беше обучен исклучиво на мојот компјутер и ова лето тој направи неколку прилично интересни сметки. Тој модел има „само“ 615 милиони параметри, па може да се тренира на помалку графички картички. Исто така, вреди да се напомене дека во последните неколку недели повеќе поединци, како и неколку компании, финансиски го поддржаа проектот, за што сум многу благодарен! Тие се „мецените“ или покровители на проектот.
За крај Алекса Гордиќ препорачува: “Итна инвестиција во модернизирање на наставните програми поврзани со вештачката интелигенција. Ова би го вовел како задолжителен предмет од основно училиште. За жал, ми се чини дека дури и нашите најдобри колеџи како ЕТФ не се ни блиску до местото каде што треба да бидат во 2023 година. Ова мора драстично да се промени.”
Целото интервју тука