

Истражувачки тим на Мајкрософт објави нов модел на вештачка интелигенција кој го претвора текстот во говор и може да произведе сечиј глас. За новиот модел, наречен VALL-E, потребнa е само аудиоснимка од три секунди. По завршување на процесот на учење на тонот на гласот, вештачката интелигенција може да го репродуцира истиот ‘глас’ како кажува било што, истовремено одржувајќи и емотивен тон, пренесува Ars Technica.
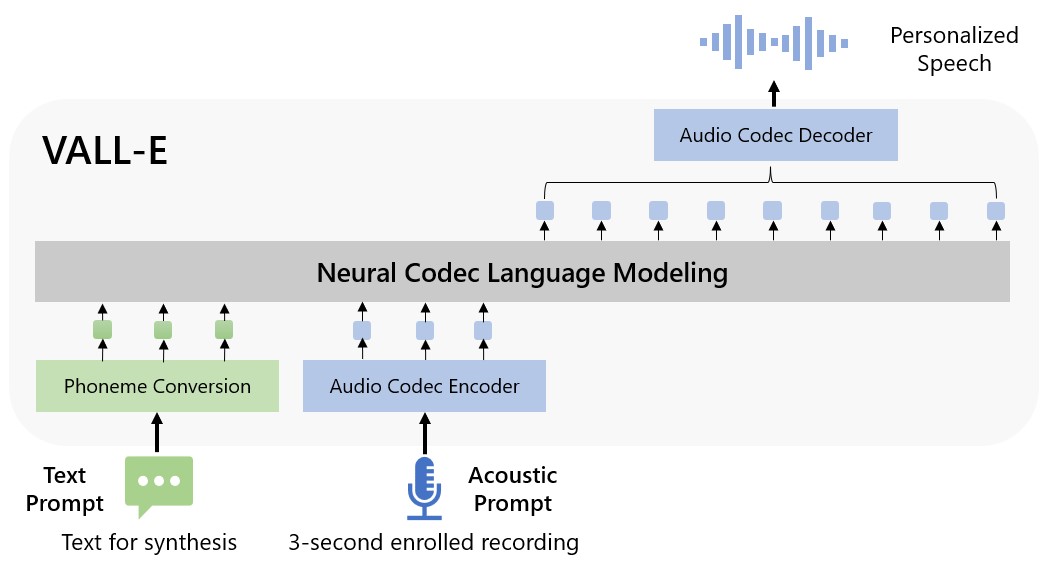
Мајкрософт го нарекол VALL-E „модел на јазик за невронски кодек“ и тој се заснова на технологијата EnCodec што Мета ја објави во октомври 2022 година. Во споредба со другите методи на „текст во говор“ кои произведуваат говор со манипулирање со брановите должини, VALL-E создава посебни кодови за аудиокодек благодарение на текстуалните и акустичните помагала. Во основа го анализира звукот/гласот од човекот, а потоа, благодарение на технологијата EnCodec , ги дели тие информации на повеќе компоненти (токени) и ги комбинира добиените информации за учење со она што “веќе го знае” за тоа како гласот би звучел кога би изговарал други фрази што ги нема на снимката.

Мајкрософт процесот го објаснил на следниов начин: „Со цел да се создаде персонализиран говор, VALL-E создава соодветни акустични токени условени од акустичните токени на претходно вчитаната звучна снимка и од начинот на формирање на фонемите, кои соодветно ги ограничуваат говорникот и содржината на говорот. На крај генерираните акустични токени се користат за создавање на конечниот звучен бран со соодветниот декодер за невронски кодек.”
Мајкрософт ја усовршувал способноста на вештачката интелигенција VALL-E да генерира говор благодарение на звучната библиотека LibriLight, составена од Мета. Самата библиотека содржи 60 000 часа говорен англиски јазик од повеќе од 7000 луѓе, снимки што се во најголем дел преземени од јавните аудио книги на LibriVox.
Компанијата Мајкрософт ги претстави резултатите од вештачката интелигенција VALL-E на својата веб-страница со примери, од кои некои звучат мошне веродостојно. Аудио снимките означени со ознаката „Speaker Prompt“ се снимки во должина од три секунди, кои VALL-E мора да ги имитира. Аудио снимката со ознака „Ground Truth“ е веќе постоечка аудио снимка од истиот говорник којашто се користи за споредба со VALL-E верзијата од истиот текст. „Baseline“ е пример од синтетички говор што го нуди стандардниот конвертор за текст во говор, додека “VALL-E” е верзијата што ја создава вештачката интелигенција VALL-E. Резултатите од експериментот се мешани – за некои гласови лесно може да се погоди дека се компјутерски генерирани, додека други резултати мошне лесно може да го заведат слушателот дека се работи за вистински глас од човек.
Со цел да се зачува гласовниот и емоционалниот тон, VALL-E може да имитира и различни акустични средини, па така за резултатот да звучи како телефонски разговор, на пример, ВИ ќе додаде и акустични ефекти, синтетизирајќи ги соодветните звучни фреквенциите за телефонски разговор.
Свесна за потенцијалниот ризик што го носи технологијата, компанијата изјави: „Бидејќи VALL-E може да го рекреира говорот што е дел од идентитетот на говорникот, технологијата со себе носи потенцијален ризик од злоупотреба. За да се избегнат ваквите ризици, можно е да се создаде детектор кој ќе утврди дали звучниот запис е создаден од VALL-E.”